Pada artikel kali ini, akan dibahas mengenai cara menganalisa sentimen masyarakat melalui media sosial Twitter terhadap kasus Bullying menggunakan aplikasi R. Tetapi, sebelum melakukan Sentiment Analysis, terlebih dahulu saya akan menjelaskan beberapa hal yang menyangkut tentang Sentiment Analysis ini. Beberapa hal diantaranya adalah:
1. Apakah itu Machine Learning?
2. Mengapa Sentiment Analysis?
3. Apakah itu Sentiment Analysis?
4. Bagaimana Sentiment Analysis bekerja?
Topik pertama yang akan sedikit saya jabarkan adalah mengenai Machine Learning, Machine Learning adalah komputer yang belajar tanpa campur tangan dari manusia, sehingga komputer tersebut dapat belajar dengan sendirinya, komputer tersebut akan belajar kapanpun mereka mendapatkan data-data baru tanpa campur tangan atau bantuan dari manusia.
Machine learning terbagi menjadi tiga kategori, yaitu Supervised Learning, Reinforcement Learning, dan Unsupervised Learning.
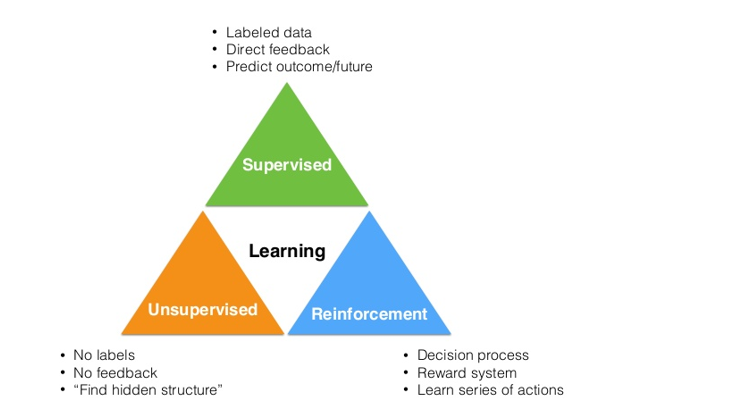
Supervised Learning adalah ketika anda
melatih/melakukan training terhadap suatu program dengan ouput yang sudah
tersedia, artinya anda melakukan training pada program dengan menggunakan data
sets, sehingga akan mengenali apa yang sedang dibahas. Contohnya bila ingin
membuat sebuah program untuk mengenali
bagaimana perbedaan jenis buah-buahan.
Pastinya anda akan
melatih/melakukan train pada program dengan berbagai macam input yang berbeda, anda
harus melatih program dengan atribut pada buah-buahan, misal menggunakan atribut
bentuk sebagai pengenal, pada buah apel bentuknya adalah bulat dan pisang
berbentuk panjang. Setelah melakukan train dengan data-data tersebut, terdapat juga satu lagi data set yang disebut dengan testing data set.
Artinya, setelah anda melatih program dengan data-data
yang beragam untuk dipelajari, kemudian
memasukan input sebagai bahan testing kedalam
program, hasil yang didapatkan dari testing tersebut adalah yang akan menentukan apakah program yang dibuat sudah akurat atau
belum. Misal, ketika anda memasukan input citra buah apel malang, namun program
tersebut mengenali bahawa gambar tersebut adalah buah pisang, maka akan
menurunkan nilai keakuratan dari program yang anda buat.
Jadi, kesimpulan dari Supervised
Learning adalah anda menyediakan data-data untuk di training/dilatih agar program
dapat berjalan dengan benar, kapanpun data-data tersebut terlibat didalam
program, biasanya Supervised Learning digunakan untuk
mengelompokan suatu data, ke data yang sudah ada. Pada contoh kasus tersebut, sebuah program yang akurat adalah,
apabila anda memasukan citra buah pisang ambon sebagai input, maka program akan
mengelompokan inputan tersebut kedalam buah pisang.
Selanjutnya, divisi machine learning yang kedua yaitu Reinforcement Learning. Reinforcement Learning adalah ketika
anda mencoba membuat keputusan berdasarkan pengalaman dimasa lalu, jadi program
akan belajar berdasarkan pola kebiasaan. Misal, pada sebuah program tentang
ramalan cuaca, ketika anda bertanya pada program tersebut, apakah akan hujan
besok, maka program tersebut akan mengambil keputusan berdasarkan keadaan yang
lalu, apakah hujan atau tidak, dan beralih kehari sebelumnya lagi dan
menganalisis parameter apa yang mengarahkan bahwa akan hujan dihari selanjutnya.
Parameter tersebut akan di uji dengan keadaan hari ketika anda bertanya tentang
cuaca pada suatu hari di program. Apabila terjadi kecocokan paramter ,maka
program akan memberikan keputusan.
Divisi machine learning yang terakhir adalah Unsupervised Learning, divisi ini
adalah kebalikan dari Supervised
Learning, pada Unsepervised Learning
tidak ada training data atau testing input, program tersebut akan
secara langsung memulai untuk melakukan pengelompokan berdasarkan data yang ada.
Pada divisi ini program akan melakukan klasifikasi berdasarkan cluster dan logic. Program hanya mengandalakn logika berdasarkan cluster yang
kemudian diklasifikasikan.
Misalnya, ketika anda memasukan citra buah-buahan sebagai
inputan, seperti apel malang, apel import merah, pisang raja, dan pisang ambon
kedalam program, maka program tersebut akan mengklasifikasikan inputan tersebut
secara langsung dengan menggunakan logika, tanpa adanya training terhadap data
set atau testing input.
Pada pembahasan
selanjutnya saya akan mebahasa tentang mengapa menggunakan Sentiment Analysis? Apakah
Sentiment Anlysis itu?
Sentiment Analysis adalah bagian dari Survised Learning, Bila mengambil contoh ketika anda membuat sebuah
aplikasi yang sangat populer dan memiliki jutaan bahkan miliaran pengguna,
ketika menambhakan fungsi baru pada aplikasi tersebut, anda ingin mengatahui
bagaiamana respon pengguna terhadap fungsi baru yang anda tambahkan tersebut.
Bisa saja anda mendapatkan positive atau negative respon, anda harus membuat
pertimbangan, apabila respon Negatif lebih banyak daripada respon postif, maka
itu merupakan kejadian yang buruk. Update terhadap fungsi baru yang anda
lakukan berarti buruk untuk pengguna.
Tetapi, bagaiman cara anda menentukan komentar teresebut baik
atau komentar buruk? Disinilah digunakannya Sentiment Analysis. Jadi, dasar
dari Sentiment Analysis adalah, seusatu yang akan anda lakukan ketika memiliki
komentar dengan menganalisanya apakah komentar tersebut bermuatan postive atau
negative. Adapun Sentiment Analysis ini adalah bagian dari Survised Learning yang sebelumnya pernah dijabarkan.
Bila kita berbicara mengenai Sentiment Analysis, umumnya
terdapat tiga jenis emosi yang kita dapatkan dalam sebuah kalimat komentar,
yaitu komentar Positif, komentar Negatif dan komentar Netral. Jadi
kesimpulannya, Sentiment Analysis mengidentifikasi dan mengkatagorikan opini
yang di ekspresikan lewat sebuah text dari seorang customer, baik melaui media sosial seperti Facebook, Twitter,
Instagram, Youtube, Google Play dan lain-lain.
Sentiment Analysis
Bekerja

Selanjutnya, saya akan membahas sedikit mengenai bagaimana Sentiment
Analysis bekerja. Mungkin anda akan berfikir bahwa ini adalah sesuatu yang
sangat kompleks, untuk mengetahui sebuah emosi pengguna dalam suatu komentar,
tetapi sebenarnya ini sangat sederhana.
Jadi, pada dasarnya anda memiliki dua buah kata ketika melakukan Sentiment Analysis. Anda memiliki
kata-kata Positif dan kata-kata Negatif,
dan juga ada kata-kata selain positive dan Negatif yaitu kata-kata Netral. Kata-kata tersebut adalah gudang data
anda. Sehingga, ketika terdapat sebuah Statement yang diuji , dalam analisa Statement ini akan dicocokan terhadap
dua data atau dua file, yaitu file yang berisi kata-kata Positif, dan file yang
berisi kata-kata Negatif. Kemudian, kita akan menentukan apakah kalimat
tersebut Positif atau Negatif.
 |
Contoh menentukan
sentiment terhadap Iphone 7
|
Selanjutnya kata-kata Positif dan Negatif tersebut diberikan
nilai, yang nantinya akan dijumlahkan. Untuk kata-kata Positif berbobot nilai
+1 dan kata-kata Negatif berbobot nilai -1. Dalam satu kalimat, akan dihitung
jumlah dari kata-kata yang terdapat didalamnya. Apabila jumlah dari hasil yang
didapatkan adalah bilangan Positif yang
lebih dari 0, menandakan bahwa kalimat tersebut bermuatan dengan banyak
kata-kata Positif, maka kalimat tersebut akan diputuskan sebagai kalimat Positif.
Kebalikan dari kejadian tersebut, apabila suatu kalimat
ketika dijumlahakan memiliki Score Negatif
yang kurang dari 0, maka kalimat tersebut banyak mengandung kata-kata Negatif.
Sedangkan apabila suatu kalimat, ketika dijumlahkan menghasilkan 0, maka
kalimat tersebut merupakan kalimat yang Netral.

Lalu, bagaimana apabila terdapat dua kalimat yang saling
bertolak belakang? Seperti contoh yang ada pada gambar dibawah ini. Terdapat
kalimat “The Service was Terrible but the food was Great”. Bagaimana anda akan
mengevaluasi kalimat ini? Pada bagian awal kalimat, berisi Negatif komen, sedangkan
pada bagian yang kedua berisi Positif komen.
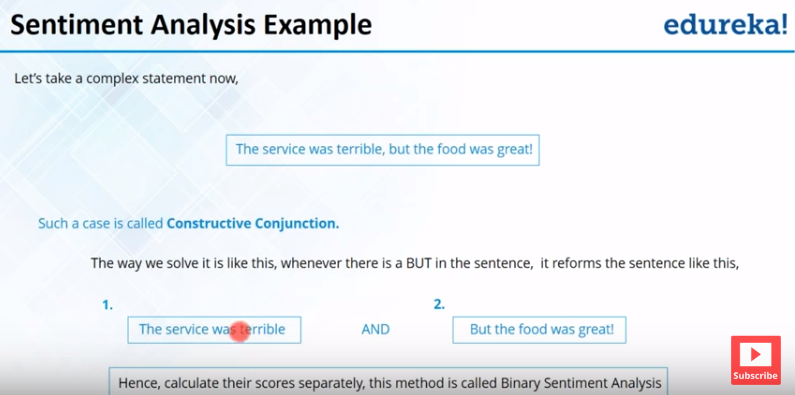
Berdasarkan persepsi manusia, apabila anda seseorang yang
mendahulukan pelayanan, maka komentar ini akan masuk sebagai komentar Negatif,
berbeda apabila anda seorang pecinta makanan, maka komentar ini akan anda
anggap sebagai komentar positi. Lalu bagaimana dengan yang komputer artikan?
Kasus ini disebut dengan Constructive
Conjunction. Dimana kaliamat ini akan dibagi menjadi dua. Jadi, kalimat ini
akan dievaluasi secara terpisah dan juga akan di list secara terpisah, sehingga
kita memiliki dua scores dan
disebagai gantinya, dari satu kalimat
akan didapatkan dua kalimat. Metode penyelesaian ini bernama Binary Sentiment
Analysis, karena anda akan membagi menjadi dua bagian dan akan dievaluasi lagi.
Sama seperti method ini, ada banyak lagi method yang dapat digunakan yang dapat
melakukan evaluasi dengan data yang lebih kompleks.
Sehingga, bila anda menginginkan untuk meningkatkan
keakuratan dari model yang and buat maka lakukan cara tertentu, sebab kita
tidak dapat langsung menyebutkan jenis
dari suatu kalimat secara tepat karena bahasa manusia adalah sesuatu yang
besar.
Sumber: https://www.youtube.com/watch?v=-JW6_kcHDj4&t=412s
Sumber: https://www.youtube.com/watch?v=-JW6_kcHDj4&t=412s
Komentar
Posting Komentar